InstaRank v2
Today, we’re excited to announce the release of InstaRank v2, an update to our InstaRank algorithm, which identifies popular, high-quality content across Instapaper. In this update, InstaRank will retain its focus on identifying high-quality content but with an added emphasis on discovering great material from less popular domains.
In the almost two years since we introduced InstaRank v1, the algorithm has become an important part of the Instapaper experience. Many Instapaper features are powered by InstaRank, including Popularity Sort in the mobile apps, the Instapaper Daily page, and its cousin, the Instapaper Weekly newsletter. Since the initial launch of InstaRank, minor changes such as profanity-filters for article text/title and domain-based checks (e.g., porn, deal-pages) have been introduced to the ranking algorithm on an ad hoc basis. Now, we are tweaking how InstaRank works to discover high quality content from less expected sources.
The hypothesis underlying InstaRank was that saves, reads, and likes on an article within Instapaper provide rich signals for intent, attention, and endorsements powered solely from actions taken by Instapaper users. Contrary to other ranking algorithms on the web, which reward social shares, InstaRank v1 was primarily driven by intent and attention-based signals from saving and reading, respectively.
Instapaper users save links from more than 26,000 unique domains each day, however, articles from the top 5 domains (NYTimes, BBC, New Yorker, etc) make up the highest frequency of daily saves, reads, and likes within the Instapaper community. Essentially, the inherent visibility of established news sources can produce high saves for certain domains. As a result, InstaRank v1 had the tendency to favor articles from more well established domains. This behavior meant that there would be little surprise in the content being marked as high quality by InstaRank.
However, this also meant that the algorithm could miss really good articles in the long tail that were of high quality but whose sources were lacking in previously established visibility, such as an individual’s blog or a newly launched publication. Instarank v2 aims to balance the scoring of articles between both high- and low-visibility domains by introducing serendipity to the algorithm.
Serendipity is a huge element in improving our digital experience in an age of information overload. And, generally speaking, serendipity often lies in the long tail. InstaRank v2 maintains a hyper-heuristic (rule) that has the ability to pick articles from newer or lesser-known domains and blogs that have prolific content. Simply put, we’re aware that our users know that they can get high quality content from sources like Ars Technica, Wired, and the New York Times. Likewise, we get that the reason our users know this, and those sources’ general prominence, is because they have historically produced high quality content. With the updated InstaRank, we aim to keep showcasing great content from sources our readers trust while also bringing to light new, exciting writing you might not come across otherwise, all with the aim of even further improving the Instapaper experience.
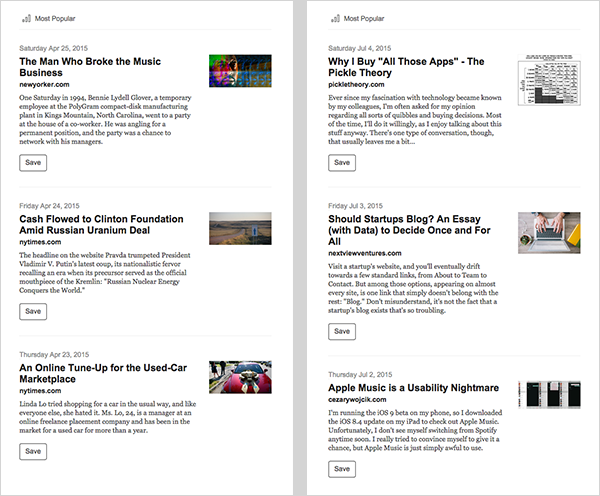
You can see the difference between InstaRank v1 and InstaRank v2 by comparing the Instapaper Weekly newsletter from April 26th (left) and July 5th (right):
If you have any questions about InstaRank or anything else Instapaper, please reach us at support@help.instapaper.com or @InstapaperHelp as we love to hear your feedback and are more than happy to any answer questions. Thanks, as always, for using Instapaper.
- Suman Deb Roy, betaworks data science team